Codex: The Frugal Developer's Salvation
Repository: codex_with_cc
I am Xiao Daidai.
Users of Cursor or Claude Code are no strangers to relentless token consumption.
Monthly bills of $300–$400 are not uncommon among heavy users.
Consider my own case.
This month, $10 spent on Codex yielded results that once required $300.
Skeptical reactions are common; hence the methods outlined below.
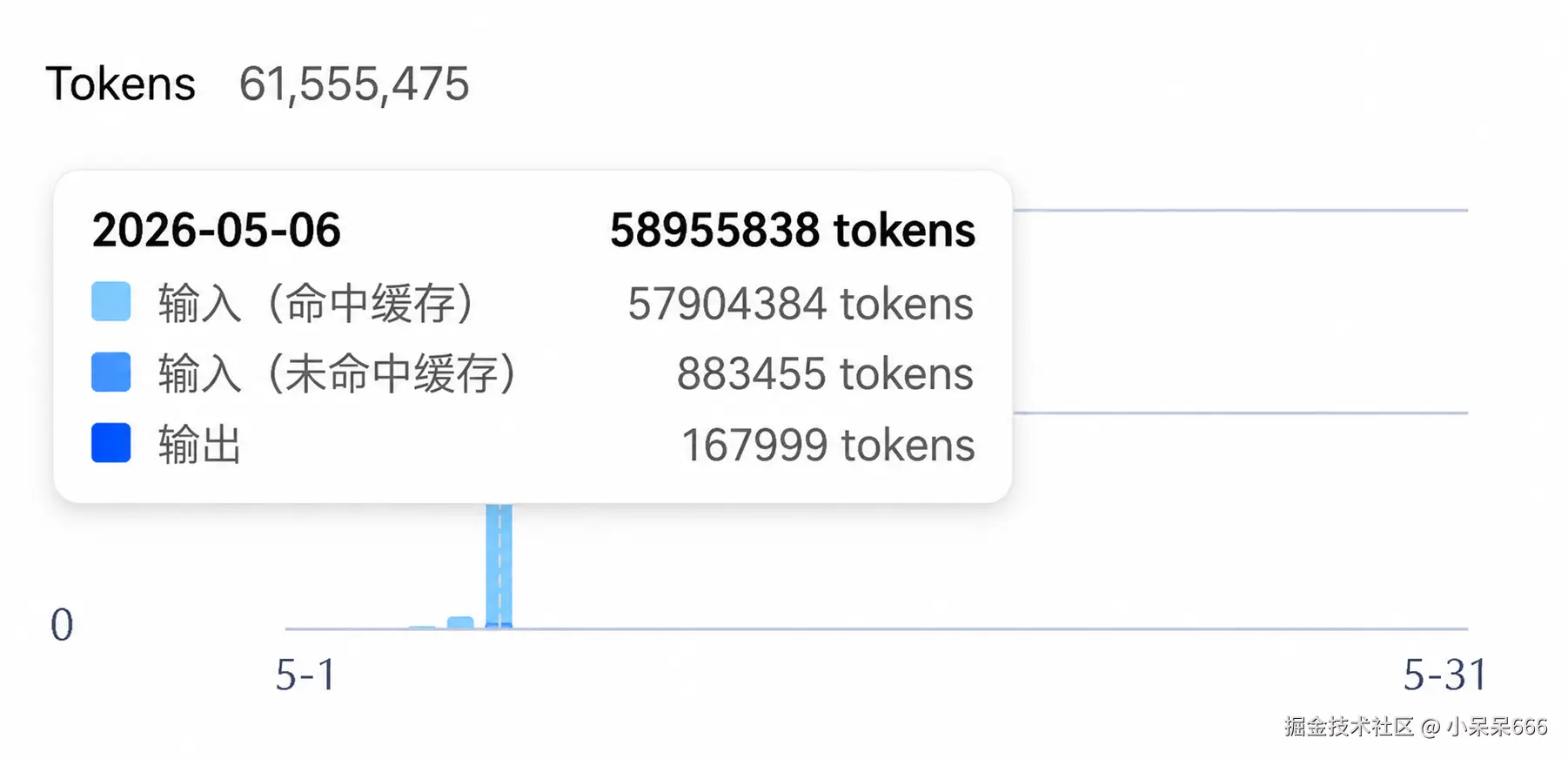
First, examine where the money goes.
LLM pricing tables are a dizzying spectacle (Figure 1).
Unlimited subscription tiers:
- Cursor Pro: $20/month for 500 requests
- GitHub Copilot: $10/month, rate-limited
- Cursor Pro: $20–$200 across tier levels (Figure 2)
- Windsurf Pro: $15/month (Figure 3)
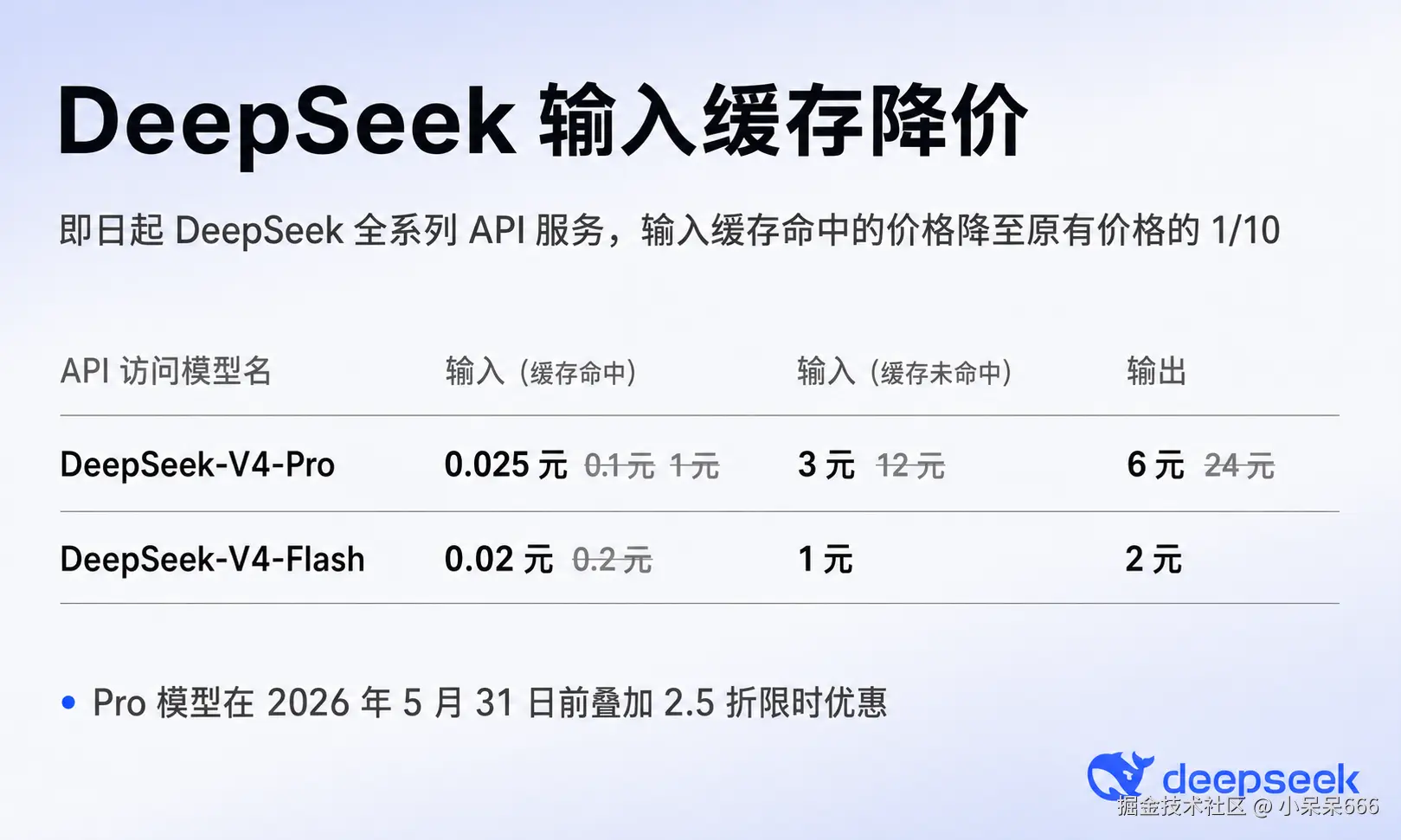
A critical evaluation of these unlimited plans is warranted.
Reasoning model pricing comparison:
- Claude Sonnet 4.6: $17.51/1M tokens
- Gemini 2.5 Pro: $1.25–$2.50/1M tokens
At $20, Gemini 2.5 Pro delivers 16 million tokens.
Cursor, by comparison, grants a mere 500 requests per month — demonstrably insufficient.
How, then, can Codex costs be reduced?
The answer is straightforward.

Codex model pricing comparison (per 1M tokens):
| Model | Input Price | Output Price |
| --- | --- | --- |
| o3 | $10 | $40 |
| GPT-5.4 | $10 | $40 |
| GPT-5.2 | $6 | $24 |
| GPT-5.4-mini | $0.15 | $0.60 |
| Gemini 2.5 Pro | $1.25 | $5 |
| Gemini 2.5 Flash | $0.15 | $0.60 |
| DeepSeek V4 0324 | $0.35 | $1.40 |
| DeepSeek V4 Flash | $0.08 | $0.32 |
For use cases where DeepSeek V4 Flash performs adequately, it warrants consideration as a primary model given its exceptionally low cost.
Cost reduction is achieved by specifying a model via .codexconfig or in-context dialogue.
A common misconception is that cost savings derive from minimizing long-context model usage. The reality is more nuanced.
Not all Codex tasks demand long-context models; for routine coding work, 128K proves adequate.
Model selection should be tailored to task complexity: o3 for complex reasoning, 5.4-mini or DeepSeek for coding, and free models for simple tasks.
External API usage further necessitates a relay service for third-party model invocation.
This method eliminates the need for an OpenAI payment method, enabling direct Codex access — even for users in unsupported regions.
A relay service effectively eliminates tax and ancillary overhead.
Yet a critical point is frequently overlooked amid the cost-saving awareness.
For further savings, share your perspective in the comments or follow 'Xiao Daidai' on WeChat for ongoing cost-optimization insights.